4
Attention: How Actions "See" Observations
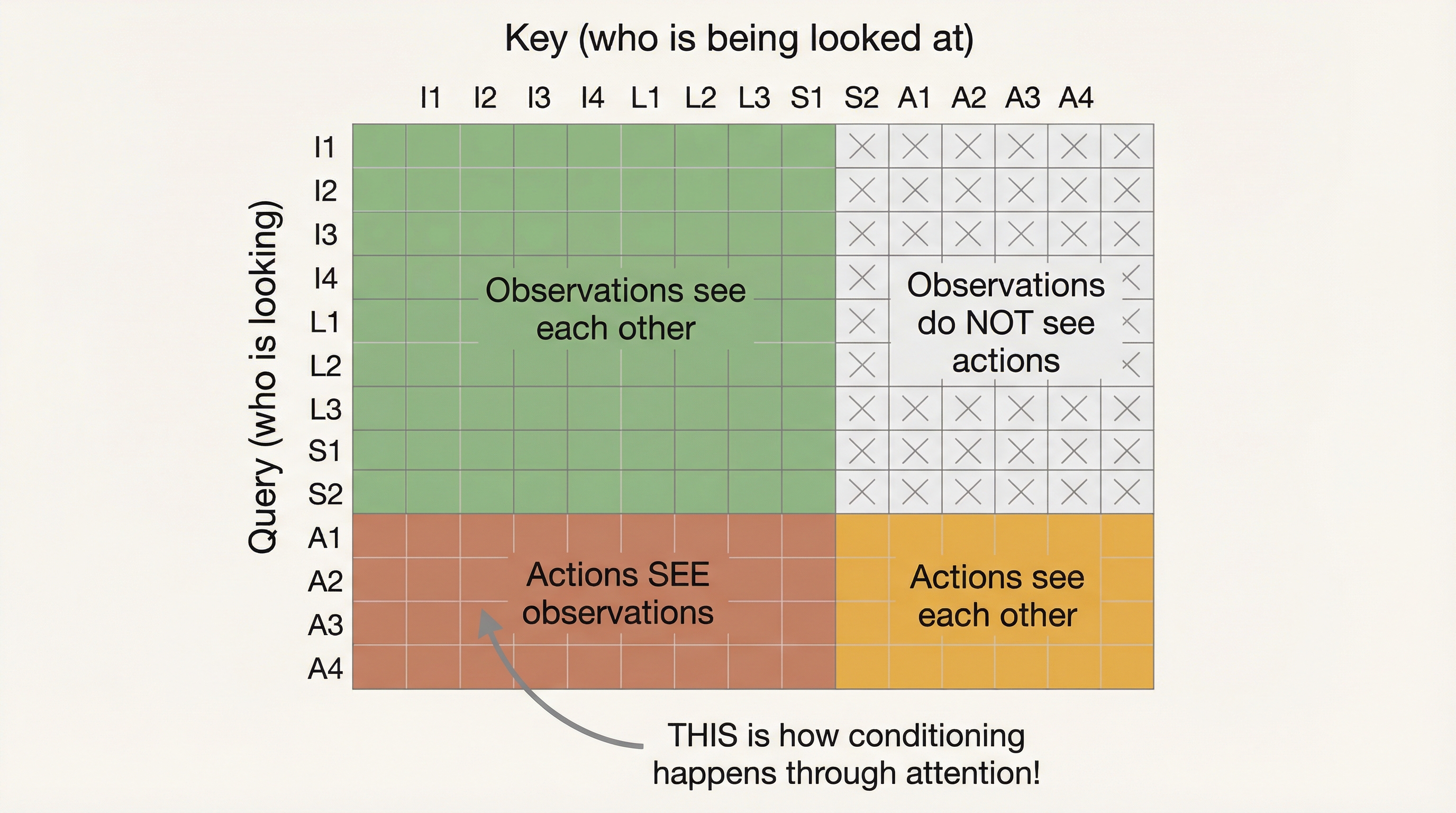
This is the core mechanism. The attention mask controls which tokens can look at which other tokens. Hover over any cell in the matrix below.
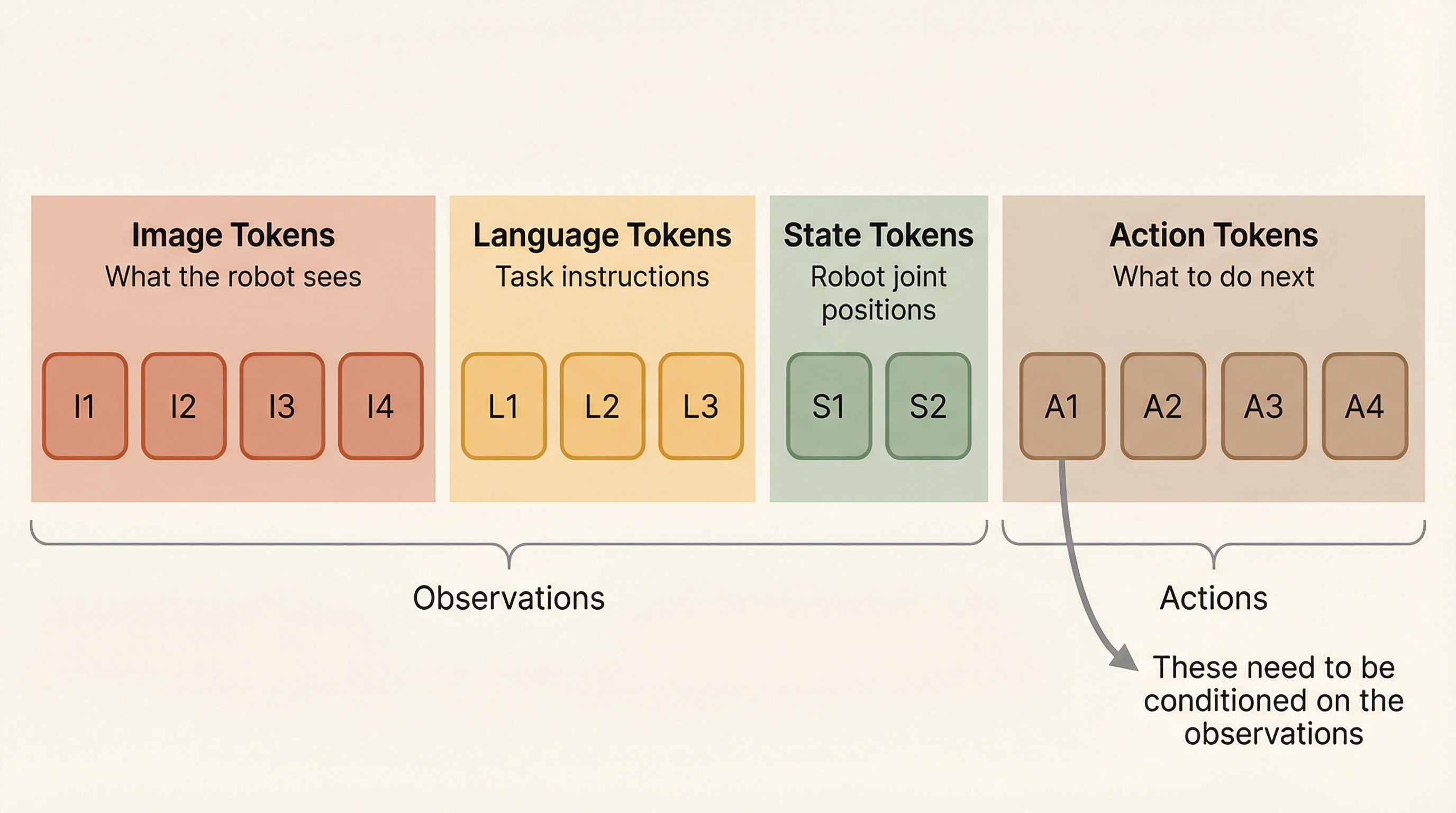
Observations see observations
Key (who is being looked at) →
Hover over a cell in the matrix
See which tokens can attend to which — and understand how actions get conditioned on observations.
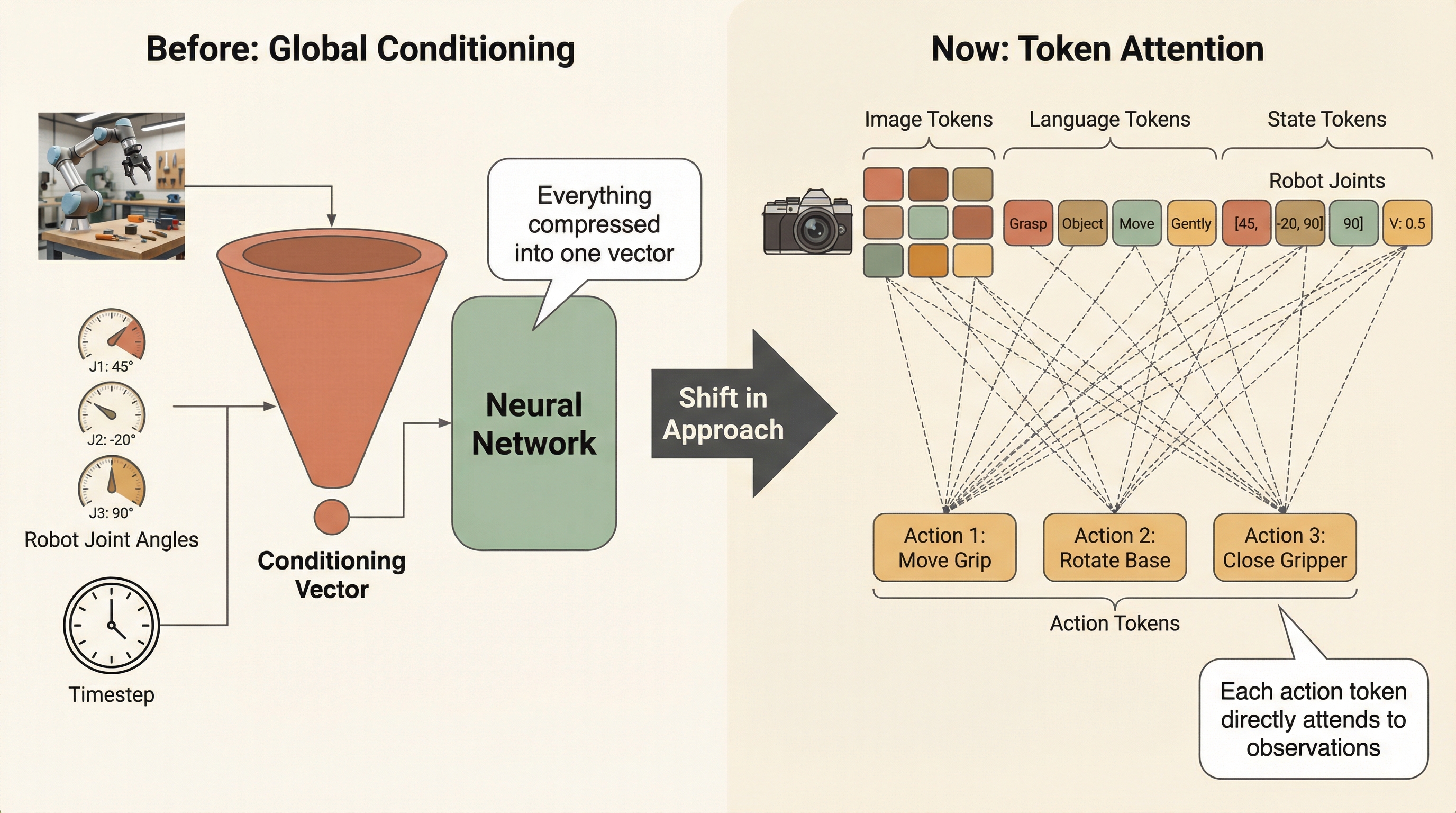
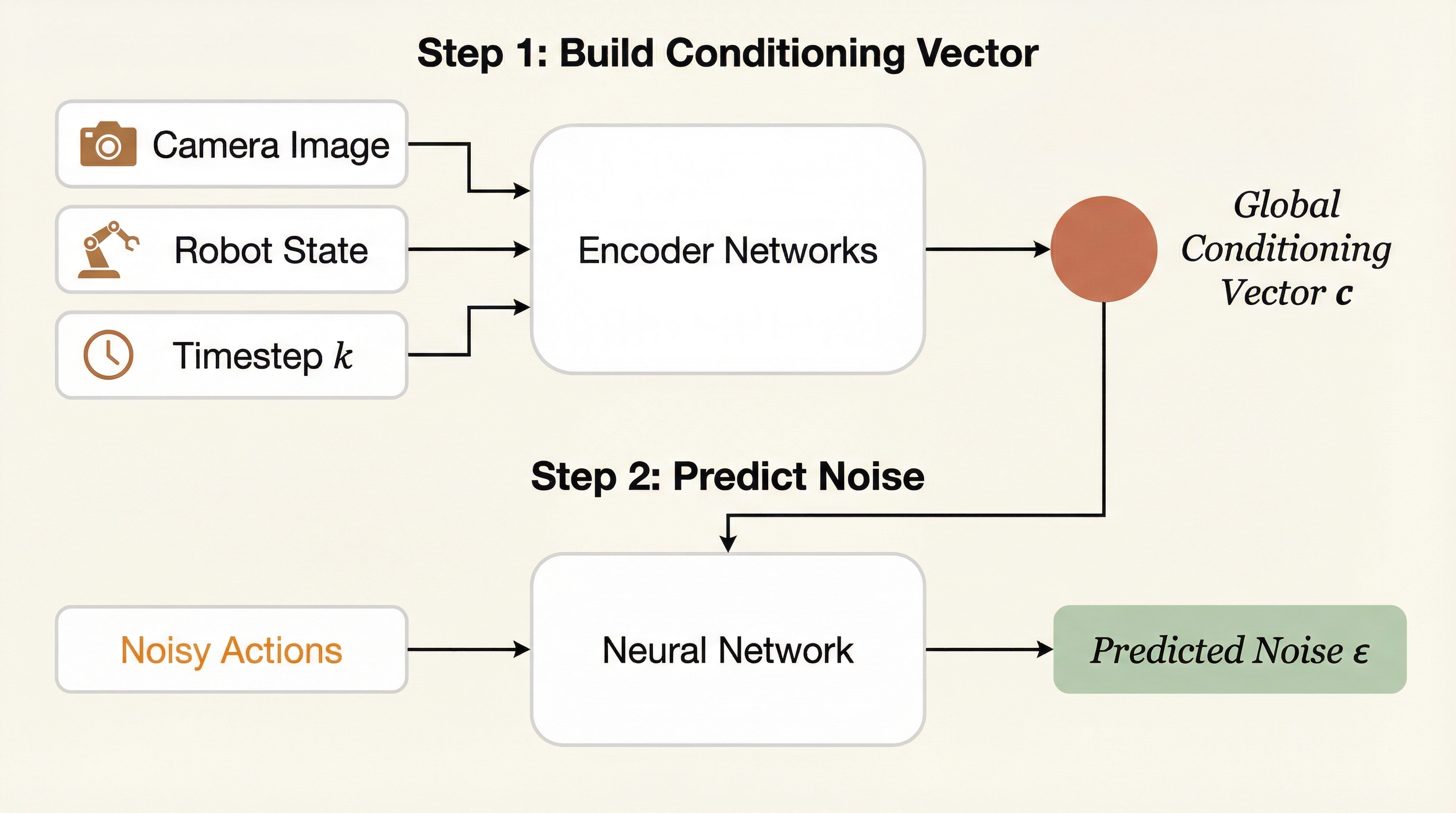
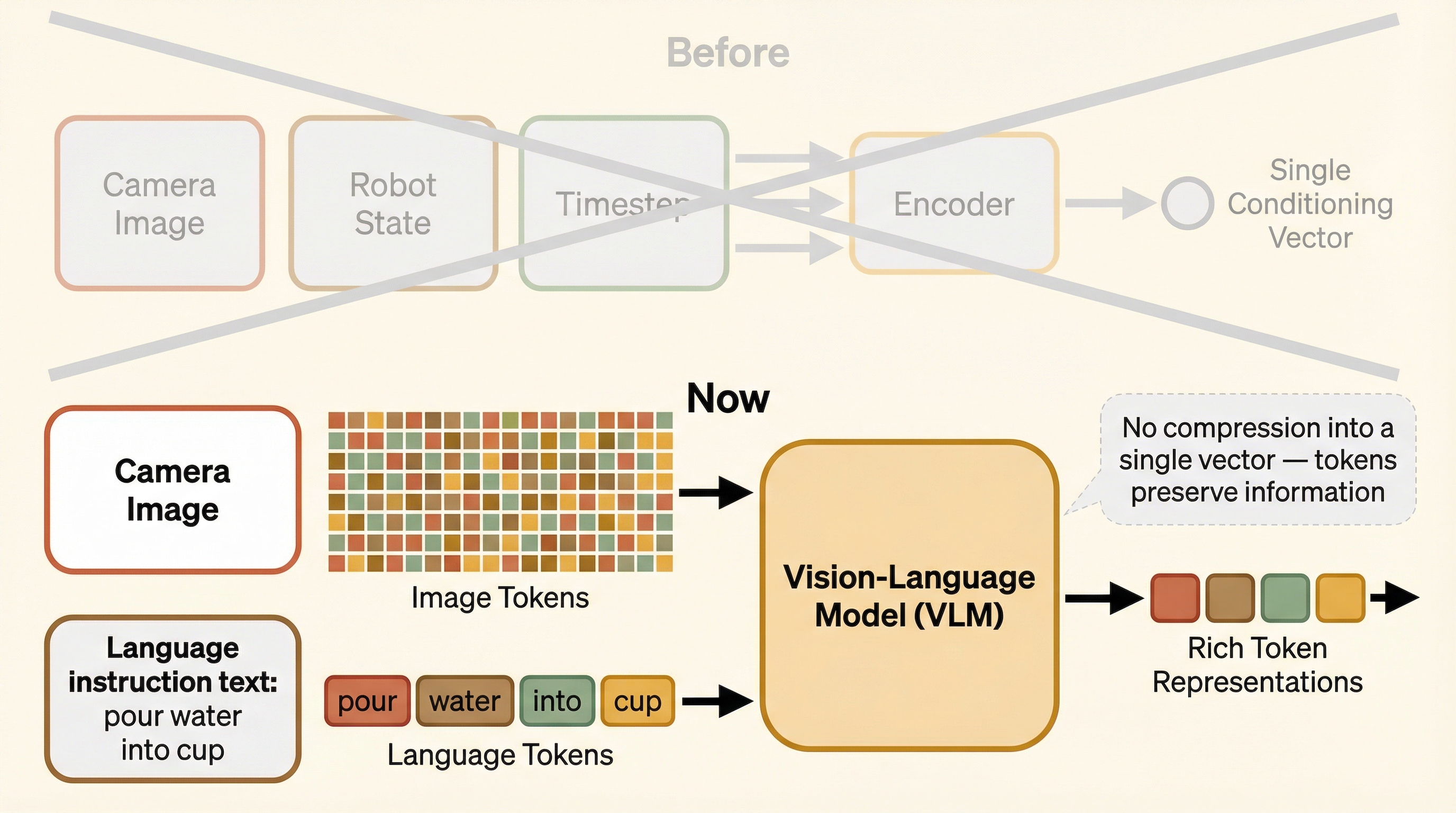
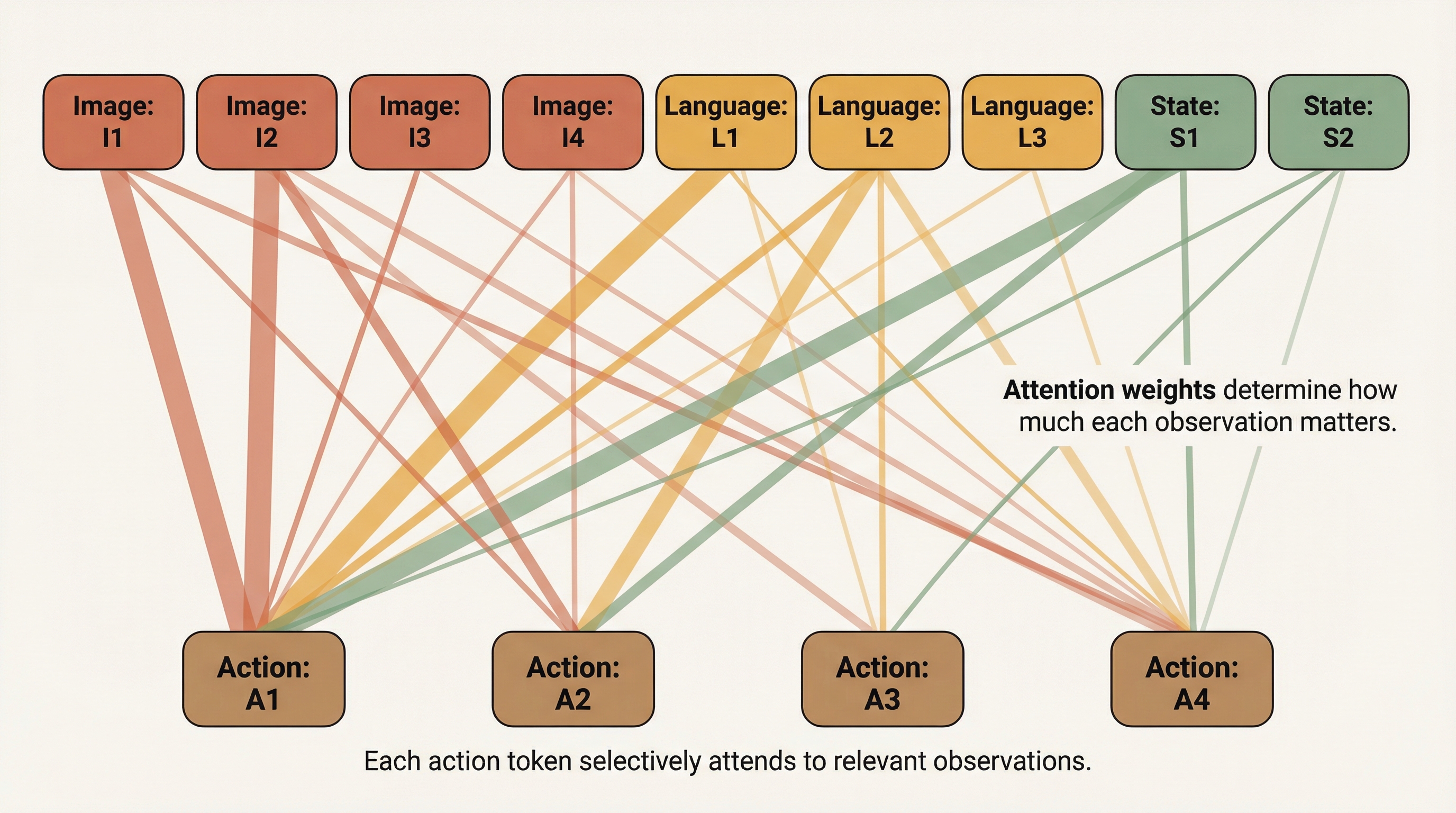
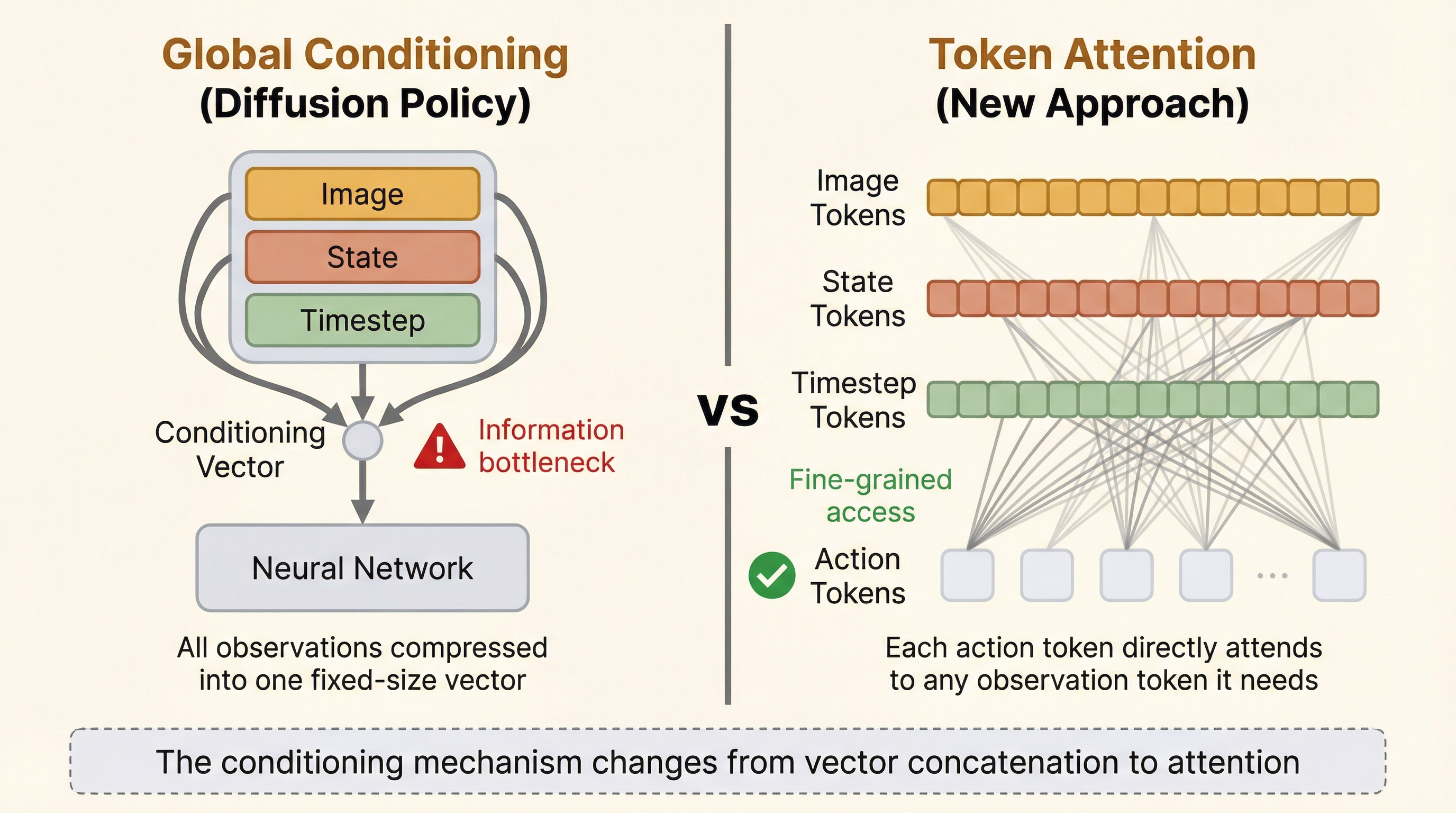
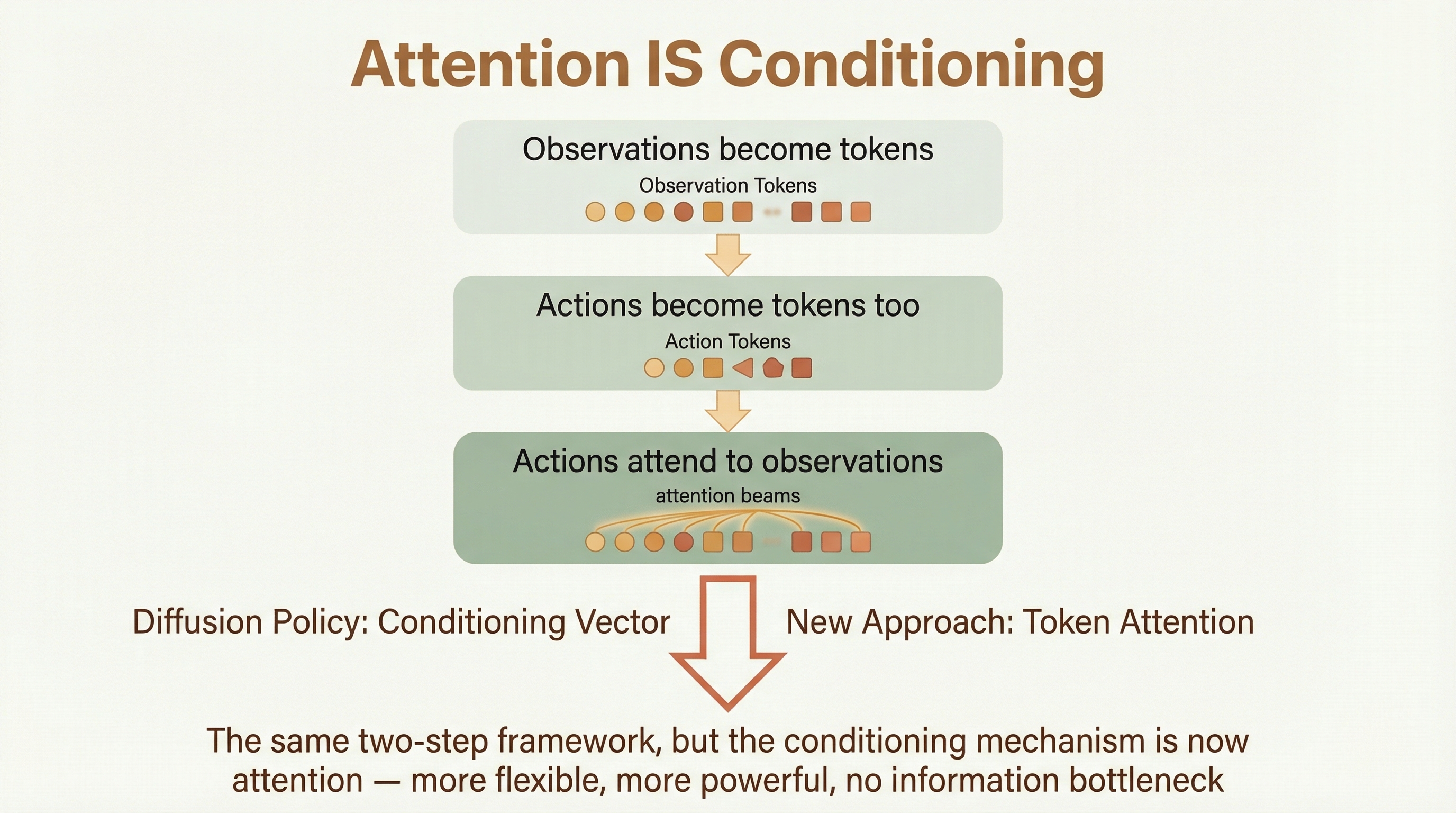
The "aha" moment: Look at the bottom-left block (terracotta). Every action token can attend to every observation token. This IS the conditioning — instead of a single vector, each action token directly queries the observations it needs through attention.